DarkSight
Interpreting Deep Classifier by Visual Distillation of Dark Knowledge
Kai Xu, Dae Hoon Park, Chang Yi and Charles Sutton

Interpreting black box classifiers, such as deep networks, allows an analyst to validate a classifier before it is deployed in a high-stakes setting. A natural idea is to visualize the deep network’s representations, so as to “see what the network sees”. In this paper, we demonstrate that standard dimension reduction methods in this setting can yield uninformative or even misleading visualizations. Instead, we present DarkSight, which visually summarizes the predictions of a classifier in a way inspired by notion of dark knowledge. DarkSight embeds the data points into a low-dimensional space such that it is easy to compress the deep classifier into a simpler one, essentially combining model compression and dimension reduction. We compare DarkSight against t-SNE both qualitatively and quantitatively, demonstrating that DarkSight visualizations are more informative. Our method additionally yields a new confidence measure based on dark knowledge by quantifying how unusual a given vector of predictions is.

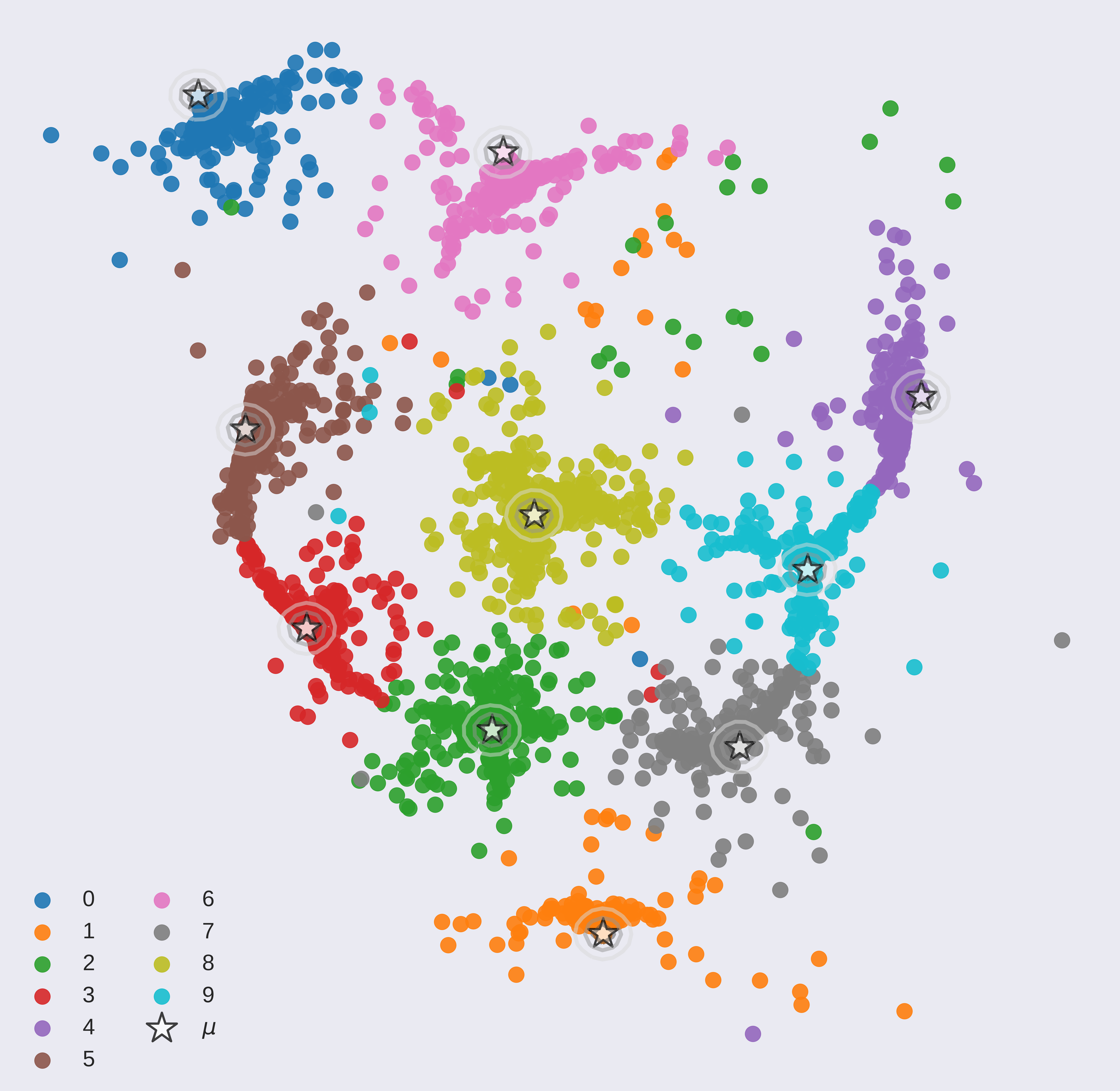
Outlier detection can be done by simply picking instances on the corner of the scatter plot or using a confidence measure based on density of DarkSight embedding. Some outliers detected are:

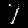
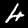







DarkSight is trained in O(N) and is GPU friendly. With the PyTorch implementation we provided in GitHub, DarkSight plot for a 10-class classifier on 10,000 instances can be generated within around 1.5 minutes with a single GPU.
Most closely related work to ours is the proposal by Andrej Karpathy to apply t-SNE to the features from the second to last layer in a deep classifier, producing a two-dimensional embedding in which nearby data items have similar high-level features according to the network. However, we observe that these plots can be misleading because they contain well-separated clusters even when, in fact, there are many points nearby the decision boundary.